برای بدست اوردن اطلاعات کلاس ها و ... ک بدرد ادیتور و موتور میخوره و لازمه . همون ک شما اسمشو گذاشتی metadata
چند تا راه وجود داره ی راهش ک تو انریل انجین استفاده شده اینه شما بیای ی چیز جانبی بنویسی که سرفایل ها رو بخونه و اطلاعات رو بهت بده.
اینطوری دیگه اون شلوغی و بی نظمی رو نداره.
بله انریل و همینطور Qt چنین ابزاریو دارند ولی پیاده سازی چنین چیزی برای یه پروژه در حد کار من خیلی سنگینه و ممکن نیست و از طرفی هم portable بودن کد هارو از بین میبره یعنی شما برای کامپایل همیشه نیاز به این ابزار جانبی داری. اما راجب اسمش قطعا من چنین اسمیو روش نزاشتم و قبلا هم همین اسمو داشته:
Meta-Object Compiler
و یه مطلب جالب دیگه اینکه حتی برنامه نویس های Qt در صورت امکان ترجیح میدن یک کد portable و بدون نیاز به یک ابزار جانبی مثل moc داشته باشن:
http://woboq.com/blog/reflection-in-cpp-and-qt-moc.html
روش دوم ک همین ماکروهای شماست با استفاده درست از سی++11 خیلی ساده تر میشه طوری ک ی ماکرو فقط نام متغییر رو بگیره همین.
من قدیما اینو نوشه بودم. ازین بهتر هم میشه کرد.
روش های دیگم هست.
اینی کشما نوشتی چند تا مشکل داره از نظر من یکی اینکه کوتاه نیست.
کدهاتونو دیدم اما کوتاهی خاصیو ندیدم و ماکروها بیشتر از یک خط رو اشغال میکنند و از property ها هم پشتیبانی نمیکنن, منظورم از پروپرتی یک متغییر ساده نیست که با یک افست ساده وبدون هیچ کنترل و فوق العاده مستعد خطا قابل دسترسی باشه. میدونید که این offset استاندارد نیست و کاملا وابسته به کامپایلر هست و به هیچ عنوان نمیشه برای خواندن یا نوشتن اشیاء روی این offset حساب کرد!
اما من راجب این کوتاهی وسادگی بیشتر تغییراتی دادم که در نسخه بعدی میبینید. بجز تعریف پروپرتی ها که تو هر جای دیگه (unreal,qt,...) حداقل نیاز به یک خط تعریف ماکرو دارن بقیه موارد کاملا در یک خط خلاصه میشن و تعریف ماکروها کاملا در یک خط خلاصه میشه! نمونه ای که در نسخه بعد موجوده:
struct KColor : public KProperty<KColor> {
KColor(U8 R = 255, U8 G = 255, U8 B = 255, U8 A = 255) :
r(R / 255.0f), g(G / 255.0f), b(B / 255.0f), a(A / 255.0f) {}
KColor(KColorTypes HexCode) {
r = ((U8)((HexCode >> 16) & 0xFF)) / 255.0f;
g = ((U8)((HexCode >> 8) & 0xFF)) / 255.0f;
b = ((U8)((HexCode)& 0xFF)) / 255.0f;
a = 1.0;
}
inline F32 getGLR() const { return r; }
inline U8 getR() const { return (U8)(r * 255.0f); }
inline void setR(U8 R) { r = (R / 255.0f); }
inline F32 getGLG() const { return g; }
inline U8 getG() const { return (U8)(g * 255.0f); }
inline void setG(U8 G) { g = (G / 255.0f); }
inline F32 getGLB() const { return b; }
inline U8 getB() const { return (U8)(b * 255.0f); }
inline void setB(U8 B) { b = (B / 255.0f); }
inline F32 getGLA() const { return a; }
inline U8 getA() const { return (U8)(a * 255.0f); }
inline void setA(U8 A) { a = (A / 255.0f); }
// only 1 line!
KMETACLASS(KColor);
private:
F32 r;
F32 g;
F32 b;
F32 a;
};
و دوم اینکه بخاطر گرفتن یا گذاشتن هر مقدار در واقع ی تابع صدا زده میشه ک باعث میشه مرحله یا همون محیط بازی دیر تر لود بشه.
البته تو ی بازی دو بعدی چیزی نیست.
اگه ی کلاس virtual برا کلاس بزاری ک اطلااتو سریالیز کنه اینطوری هه چی inline میشه و بخاطر هر متغیر کوچیک تابع صدا زده نمیشه.
منطورتونو کامل متوجه نشدم که این صدا زدن تابع راجب قسمت serialize یا راجب property ها هست؟؟!
اگر منطورتون property هاس که قطعا چنین چیزی (صدا زدن یک تابع برای مقدار دهی) لازمه یعنی شما اجازه ندارید یه متغییر عددی یا ... رو هرجور که دوست دارین مقدار دهی کنید و این منطق در تمام زبانهایی که از property پشتیبانی میکنن یکسانه. مثلا فرض کنید ما یک property داریم به نام health که مسئوله تنطیم مقدار سلامتی کاراکتره. بازه سلامتی کاراکتر با توجه به لول کاراکتر بینه 0 تا 100 هست. تو این شرایط چه قسمتی مسئولیت چک کردن مقدار ورودی health هست؟ شاید طراح گیم پلی مقدار 300 رو برای health pack در نظر گرفته باشه و وقتی کاراکتر health pack رو دریافت میکنه مقدار سلامتیش از نوار سلامتی هم عبور میکنه و روی 300 قرار میگیره!!!! ولی اگر ما یک تابع برای مقدار دهی متغییر health داشته باشیم این مشکل به وجود نمیاد و این تابع مقدار ورودیو کاملا چک میکنه. و البته سربار این تابع به قدری ناچیزه که شاید در بدترین حالت ممکن (مثلا یک ملیون فراخانی در هر فریم) باز هم مشکلی بوجود نمیاره و بخش property هم کاملا بصورت inline نوشته شده. و نکته مهمتر اینکه این property ها در run-time توسط اسمشون (نه یک افست) قابل دسترسی هستند چیزی که در ماکروهای شما و کلا در پیاده سازی شما ممکن نیست!
اما شاید منطورتون راجب قسمت serialize هست. اگر نمونه های مشابه مثل boost.serialization یا ... رو دیده باشین یا اصلا منطق سریالی کردنو در نطر بگیریم 2 حالت کلی بوجود میاد برای سریالی کردن یک شی. حالت اول اینه که ما کل شی رو بدونه توجه به جزئیاتش بصورت یکجا به اندازه سایزش در فایل یا ... بنویسیم. تو این حالت ما فقط به یک فراخانی تابع نیاز داریم اما مشکلاتی که وجود داره:
اشارگر ها تو این حالت ذخیره نمیشن, متغییر ها با توجه به نوع indianess در سیستم های مختلف در موقع لود شدن به مشکل میخورن , padding ساختارها که کاملا وابسته به کامپایلر هست باز هم مثل مورد قبل مشکل ایجاد میکنه و ...
اما حالت دوم (چیزی که الان در فریم ورک وجود داره) اینه که ما یک شی رو به جزئیاتش (C++� � primitive types) تجزیه کنیم و هر جزء رو بصورت کاملا مستقل با رعایت کردن تمام موارد بالا بنویسیم یا بخونیم. پیاده سازی این حالت بصورت اتوماتیک مثل نمونه ایی که الان در فریمورک پیاده شده (نه اینکه خود برنامه نویس برای هر کلاس بصورت دستی بنویسه) با تنها یک فراخانی تابع (چیزی که شما گفتید) فکر نمیکنم ممکن باشه. اگر هست لطفا مثال بزنید.
اما راجب کلاس virtual که گفتید من باز هم منطورتونو متوجه نشدم احتمالا منطورتون تابع virtual بوده! گفتید کدهارو دیدید و میدونید که من برای بخش سریالی از هیچ تابع virtual کمک نگرفتم و اصلا این قسمت هیچ سربار اضافه ایی برای توابع virtual و جستجوی v table نداره حتی توابع استفاده شده هم کاملا static هستند.
و در مورد کد نویسیت . اصلا اصولی نیست . خیلی جاها فقط کد الکی تولید شده مثلا عوض استفاده از لیست پیوندی امدی داخل همون کلاست اشاره گر به عنصر بعدی دادی و دوباره دستی همه چی رو نوشتی.
خوب قطعا کدهای اضافه ایی وجود داره که باید اصلاح بشه چون بخشی از کلاسهای core رو دوستان دیگه ایی نوشتن که من وقت نکردم اصلاحشون کنم. ولی راجب لیست پیوندی باید بگم که بعضی از کلاسها استفاده سنگینی از ساختار لیست میکنند و من دقیقا حرف شمارو در تست های اولم انجام دادم یعنی از لیست های پیوندی STL استفاده کردم اما اگر امتحان کرده باشین متوجه میشین که لیست های پیوندی STL در شرایطی که گره های زیادی رو داشته باشن همینطور که کند تر و کند تر میشن از طرفی هم شروع به بلعیدن حافظه میکنند (بصورت تساعدی!)
خوب تو این شرایط دو راه وجود داره یا باید لبست های پیوندی رو بازنویسی کنیم به همراه یک memory allocator اختصاصی یا میشه با اضافه کردن یک اشارگر ساده تمام مشکلو در کوتاترین و سریعترین حالت ممکن برطرف کنیم! که خوب بدیهیه که پروژه ایی با فقط 1 برنامه نویس راه دومو انتخاب میکنه!
اما خوب کلاس memory allocator هم از نوع stack و هم از نوع pool به زودی اضافه میشه که شاید continer های خیلی ضروری مثل لیست و وکتور رو سازگار با این کلاسها بازنویسی کردم.
درضمن این کدهایی ک تو سایت بود رو من همشو دیدم
همه موتور ک اینا نیست مطمعنا.هست؟ بقیشم بزاری بد نیست.
شایدم من درست ندیدم.
تمام کدها موجوده ولی موتوری فعلا وجود نداره! و من بار ها گفتم که این پروژه یک framework هست (نه موتور/انجین) مثل تمامه framework های دیگه (SFML - ClanLib - ....)
البته انجین/موتور تو پست قبل هم گفتم که در حاله ساخته و احتمالا در نسخه بعدی ی بخشهایی از انجین/موتور رو میتونید ببینید روی مخزن.
ممنون از اینکه نظر دادی.





 پاسخ با نقل قول
پاسخ با نقل قول

 . آفرین. تبریک.
. آفرین. تبریک.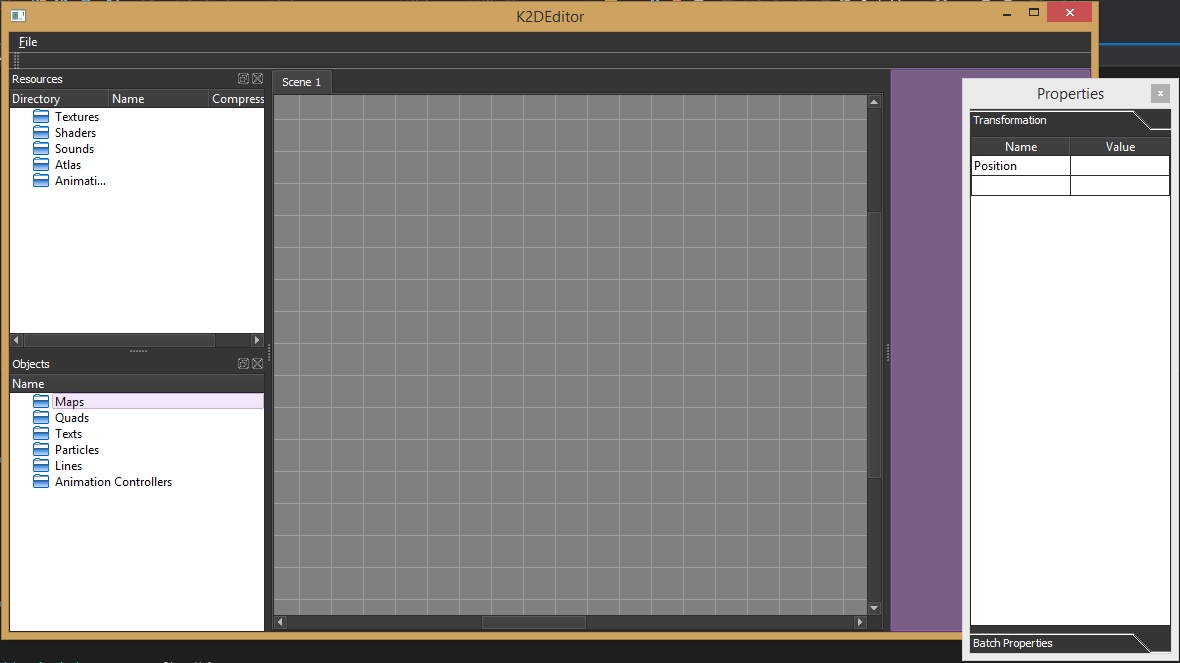



 و چون هدفتونو از این کار میدونم نیازی به وقت گزاشتن و جواب دادن نیست.
و چون هدفتونو از این کار میدونم نیازی به وقت گزاشتن و جواب دادن نیست.

 ) ولی خوشبختانه تو این مدت کارهای زیادی روی فریمورک انجام شده که بزودی روی مخزن قرار میگیره به همراه توضیحات . (نسخه 1.2)
) ولی خوشبختانه تو این مدت کارهای زیادی روی فریمورک انجام شده که بزودی روی مخزن قرار میگیره به همراه توضیحات . (نسخه 1.2)


