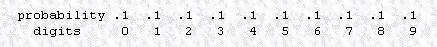Burrows-Wheeler Transform
خوب اين صفحه رو هم ميخوايم اختصاص بديم به تبديل Burrows-Wheeler که خوب همينطور که ميدونيد اين ها (Burrows و Wheeler) اسم های افرادی هستن که اين تبديل رو ارائه دادن. خوب من به زبون خيلی ساده اينجا براتون توضيح ميدم که چجوری اين تبديل کار ميکنه و بعد معکوسش رو ديگه به عهده خودتون ميزارم تا انجام بدين اگر چه که فکر نکنم کار سختی باشه.
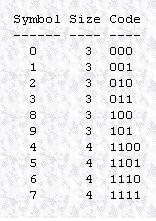
توضيح مختصری در مورد الگوريتم
خوب اولين مسئله اينه که بايد بدونيم که اين تبديل به هيچ عنوان باعث فشرده سازی نميشه و نه تنها اين بلکه حجم داده رو حتی زياد هم ميکنه ولی مسئله مهم اينه که بلوک داده ما بعد از تبديل به فرمی در مياد که با استفاده از بعضی از روش های فشرده سازی به صورت خيلی بهينه تری ميشه فشردش کرد. ولی خوب يه چيزی رو بايد هميشه يادتون باشه و اون اينه که هزينه اي که ما برای فشرده سازی بهتر پرداخت ميکنيم زمان بيشتر و حافظه بيشتری از سيستم عامل هستش.
يکی از تأثيراتی که تبديل BWT روی داده ها داره اينه که تعداد run های طولانی تری رو توليد ميکنه. که خوب حتماً ميدونيد run چی هستش ديگه؟ اگه نميدونيد بريد قسمت Run Length Encoding رو بخونيد ميفهميد چی ميگم.حالا در ادامه يه مثال ميزنم که بيشتر قضيه جا بيفته.
مثال
فرض کنيم متن زير رو ميخوايم کد کنيم :
S= "this is a test."
خوب حالا شروع ميکنيم به چرخوندن متن تا تمام حالت های زير بوجود بياد:
S0="this is a test."
S1=".this is a test"
S2="t.this is a tes"
S3="st.this is a te"
S4="est.this is a t"
S5="test.this is a "
S6=" test.this is a"
S7="a test.this is "
S8=" a test.this is"
S9="s a test.this i"
S10="is a test.this "
S11=" is a test.this"
S12="s is a test.thi"
S13="is is a test.th"
S14="his is a test.t"
.
خوب حالا تمام حالت های زير رو به ترتيب حروف الفبا مرتب می کنيم :
S8= " a test.this is"
S11= " is a test.this"
S6= " test.this is a"
S1= ".this is a test"
S7= "a test.this is "
S4= "est.this is a t"
S14= "his is a test.t"
S10= "is a test.this "
S13= "is is a test.th"
S9= "s a test.this i"
S12= "s is a test.thi"
S3= "st.this is a te"
S2= "t.this is a tes"
S5= "test.this is a "
S0= "this is a test."
خوب حالا اگه حرف آخر هر کدوم از اين s0 تا s14 رو بگيريم چی داريم؟
L="ssat tt hiies ." and I=14
همينطور که ميبينيد اين L و I که از اين مراحل بالا بدست مياد ،تبديل شده همون جمله اصلی هستش و تازه يه عدد هم بهش اضافه شده ولی ميبينيم که کاراکتر های تکراری کنار هم ظاهر شدن که اين برای بعضی روش های کدينگ خيلی مفيد هستش.
نکته جالبی که بايد مد نظرتون باشه اينه که فقط با استفاده از L و I ميشه به طور منحصر به فرد به S رسيد.که البته اين ديگه به عهده شماس که بفهمين چجوری و اصلاً هم سخت نيست.
موفق باشين
...




 پاسخ با نقل قول
پاسخ با نقل قول